MotionGlot: A Multi-Embodied Motion Generation Model
1 Brown University
Tl;dr: Techniques from Multi-lingual LLMs can be adpated to train a GPT for motion generation across embodiments with different output dimensions. MotionGlot consists of a single GPT model capable of performing a multitude of motion related tasks across multiple embodiments.
Results
Text to robot Motion
A robot walks backwards, turns right and walks forward.

A robot walks forward, turns right, and then walks backward.

A robot walks in a clockwise circular path.

Text to Human Motion
A person is running on a treadmill.

A person walks forward, and sits.

A person does cartwheel many times.

Q & A with Human Motion
How to increase leg strength?

How does a person practice in a gymnastics class?

Can you show me a move in a golf game?

Robot Goal reaching
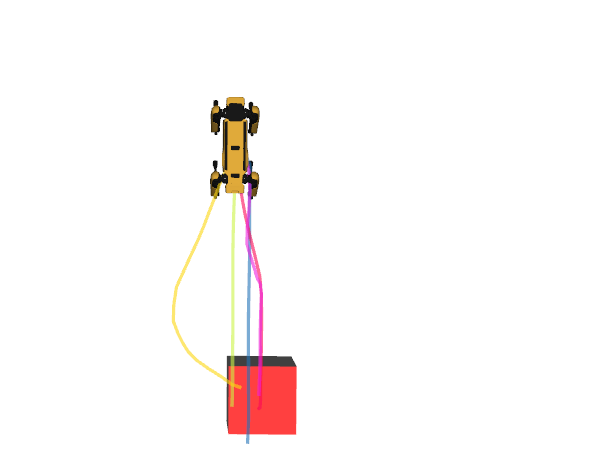
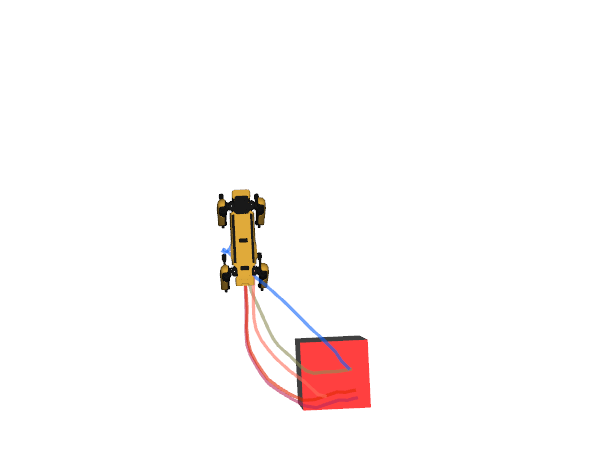
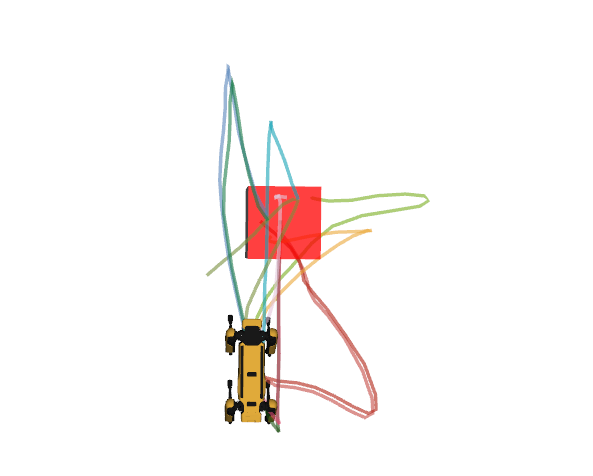
Motion Captioning
 A person marches forward with their arms swinging by the sides
A person marches forward with their arms swinging by the sides
 A person dances to waltz
A person dances to waltz
 A person is doing warm up stretches
A person is doing warm up stretches
Abstract

This paper introduces MotionGlot, a model that can generate motion across multiple embodiments with different action dimensions, such as quadruped robots and human bodies. By leveraging the well-established training procedures commonly used in large language models (LLMs), we introduce an instruction-tuning template specifically designed for motion-related tasks. Our approach demonstrates that the principles underlying LLM training can be successfully adapted to learn a wide range of motion generation tasks across multiple embodiments with different action dimensions. We demonstrate the various abilities of MotionGlot on a set of 6 tasks and report an average improvement of 35.3% across tasks. Additionally, we contribute two new datasets: (1) a dataset of expert-controlled quadruped locomotion with approximately 48,000 trajectories paired with direction-based text annotations, and (2) a dataset of over 23,000 situational text prompts for human motion generation tasks. Finally, we conduct hardware experiments to validate the capabilities of our system in real-world applications. The above figure depicts MotionGlot's ability to perform many motion-related tasks across diverse embodiments with different action dimensions.
Method Overview

MotionGlot is a GPT model which is capable of motion generation across multiple embodiments with different action spaces, the above figure depicts the overview of our approach. Our training procedure involves two steps, in the first stage (a) a VQ-VAE learns a discrete latent codebook that represents a motion vocabulary per embodiment. This process, known as motion tokenization, is similar to text tokenization.
The motion vocabulary across embodiments are then appended to the existing vocabulary of GPT-2, creating a unified motion and text vocabulary. In the second step (b), our proposed instruction template is used to train the autoregressive GPT.
Dataset
To be released Soon
Citation
@article{harithas2024motionglot,
title={MotionGlot: A Multi-Embodied Motion Generation Model},
author={Harithas, Sudarshan and Sridhar, Srinath},
journal={arXiv preprint arXiv:2410.16623},
year={2024}
}
Acknowledgements
This research was supported by the Office of Naval Research (ONR) grant N00014-22-1-259.
Contact
Sudarshan Harithas: sudarshan_harithas@brown.edu