CVPR 2025 (Highlight)
FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation
1[Brown University]
2[Meta Reality Labs]
We present FoundHand, a domain-specific image generation model that can synthesize realistic single and dual hand images.
Overview
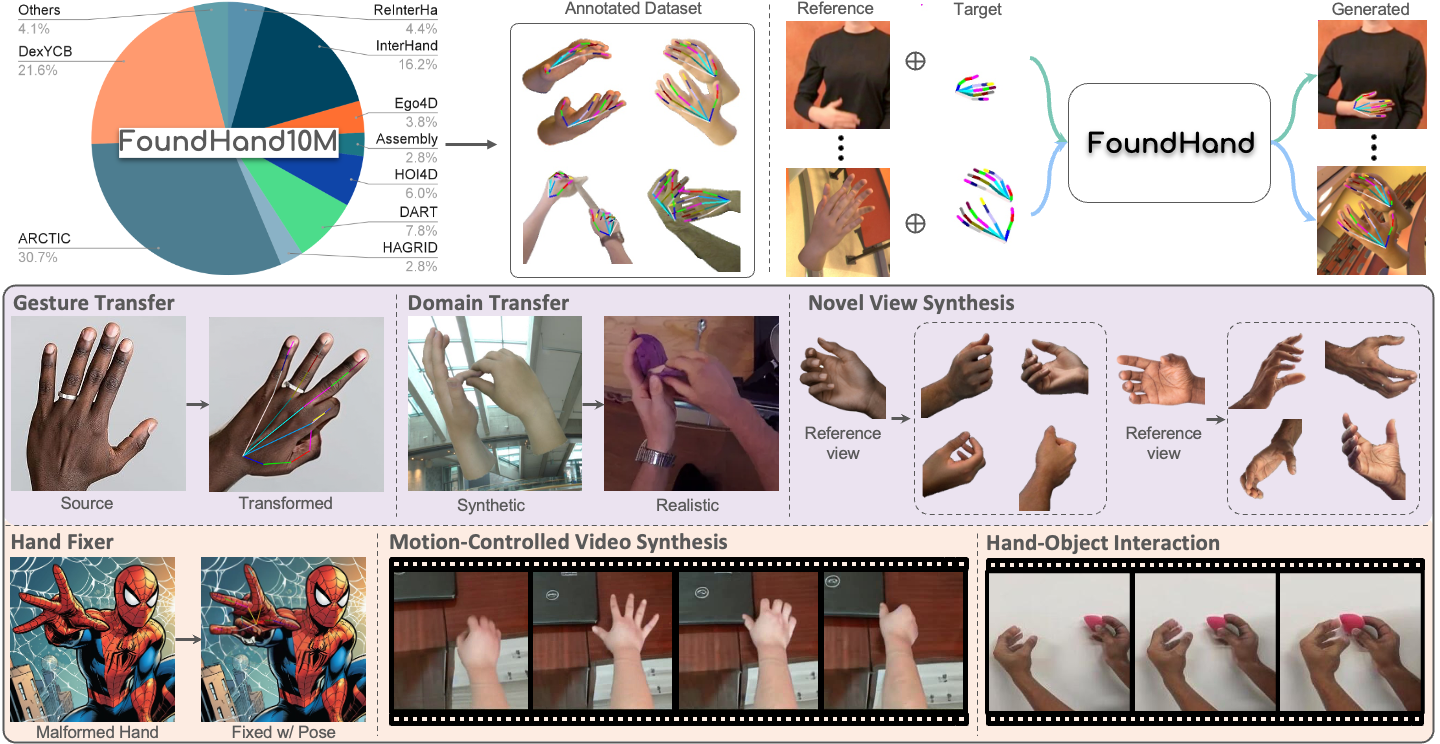
FoundHand is trained on our large-scale FoundHand-10M dataset which contains automatically extracted 2D keypoints and segmentation mask annotations (top left). FoundHand is formulated as a 2D pose-conditioned image-to-image diffusion model that enables precise hand pose and camera viewpoint control (top right). Optionally, we can condition the generation with a reference image to preserve its style (top right). Our model demonstrates exceptional in-the-wild generalization across hand-centric applications and has core capabilities. such as gesture transfer, domain transfer, and novel view synthesis (middle row). This endows FoundHand with zero-shot applications to fix malformed hand images and synthesize coherent hand and hand-object videos, without explicitly giving object cues (bottom row).
Methods
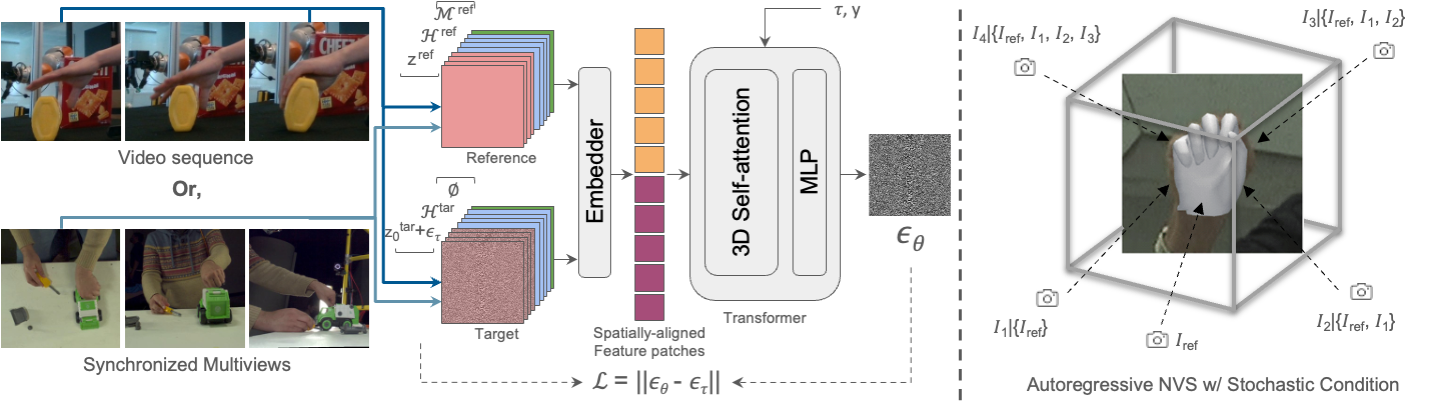
(Left) During training, we randomly sample two frames from a video sequence or two different views of a frame as the reference and target frame and encode them using a pretrained VAE as the latent diffusion model. We concatenate the encoded image features z with keypoint heatmaps H and hand mask M and encode them with a shared-weight embedder to acquire spatially-aligned feature patches before feeding to transformer with 3D self-attention. The target hand mask is set to ∅ since it is not required at test time. y indicates if the two frames are from the synchronized views.
Results
We test the generalization capability of our mdel across various 2D and 3D applications on in-the-wild web-sourced data. For more results and comparisons showing that our general model outperforms task-specific state-of-the-arts, please see our paper.
Core Capability 1: Gesture Transfer
Given reference images, our model transforms hands to target poses while faithfully preserving appearance details such as fingernails and textures.
Core Capability 2: Domain Transfer
Given a synthetic hand dataset, FoundHand can transform it to the in-the-wild domain with realistic appearance and background, improving existing 3D hand estimation after finetun- ing on our generated data.
Core Capability 3: Novel View Synthesis
From a single input image, FoundHand generates diverse viewpoints, demonstrating robust generalization to unseen hands and camera poses.
Zero-Shot Application 1: Hand Fixer
FoundHand develops zero-shot ability to fix AI-gerenated malformed hands. It works with reliable preservation of the hand appearance and hand-object interaction.
Zero-Shot Application 2: Video Synthesis
FoundHand can generate hand videos and achieves natural and anatomically plausible hand motions, without explicit video training.
Zero-Shot Application 3: Hand-Object Interaction
Without explicit object supervision, FoundHand synthesizes physically plausible object behaviors, including rigid motion (move cup) and non-rigid deformation (squish sponge), demonstrating an implicit understanding of object properties and dynamics.
Citations
@InProceedings{Chen_2025_CVPR,
author = {Chen, Kefan and Min, Chaerin and Zhang, Linguang and Hampali, Shreyas and Keskin, Cem and Sridhar, Srinath},
title = {FoundHand: Large-Scale Domain-Specific Learning for Controllable Hand Image Generation},
booktitle = {Proceedings of the Computer Vision and Pattern Recognition Conference (CVPR)},
month = {June},
year = {2025},
pages = {17448-17460}
}
Acknowledgements
Part of this work was done during Kefan (Arthur) Chen’s internship at Meta Reality Lab. This work was additionally supported by NSF CAREER grant #2143576, NASA grant #80NSSC23M0075, and an Amazon Cloud Credits Award.