WACV 2025
EgoSonics: Generating Synchronized Audio for Silent Egocentric Videos
Brown University
Generated Samples from EgoSonics (our method)
Following is a set of uncurated examples of video-to-audio generation on unseen Ego4D clips using EgoSonics (our method).
(Unmute videos to hear the audio.)
Overview
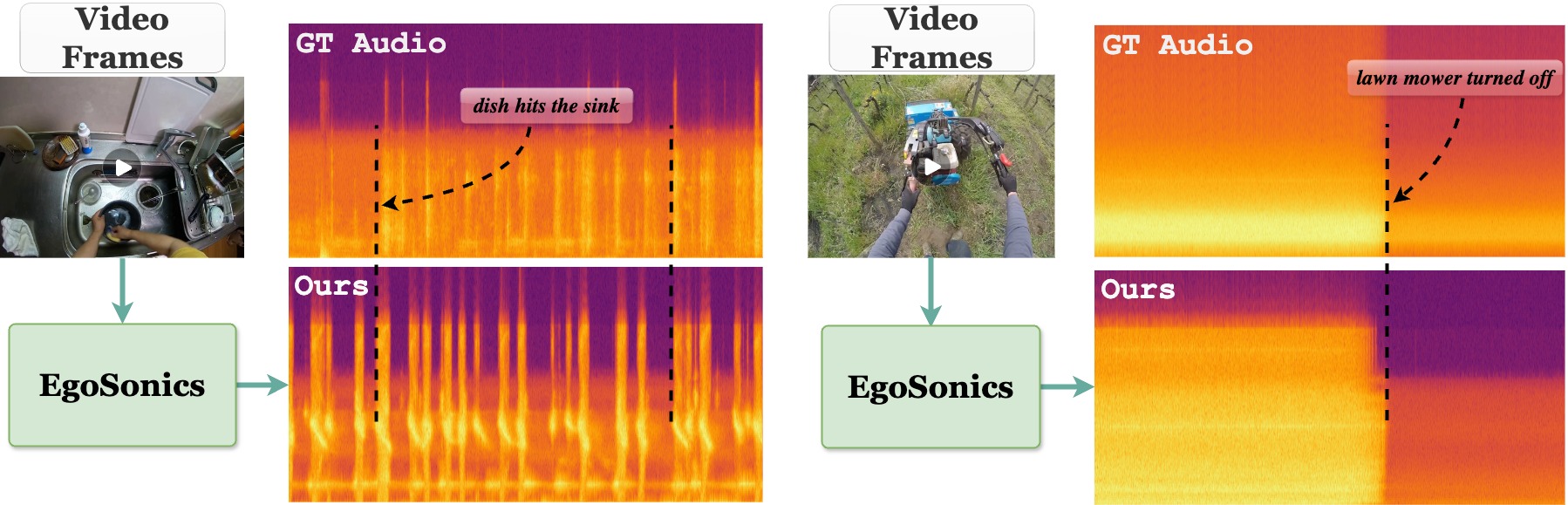
We present EgoSonics, a method to synthesize audio tracks conditioned on silent in-the-wild egocentric videos. Our method operates on videos at 30 fps to synthesize audio that is semantically meaningful and synchronized with events in the video (“dish hits the sink” or “lawn mower turned off”).
Abstract
We introduce EgoSonics, a method to generate semantically meaningful and synchronized audio tracks conditioned on silent egocentric videos. Generating audio for silent egocentric videos could open new applications in virtual reality, assistive technologies, or for augmenting existing datasets. Existing work has been limited to domains like speech, music, or impact sounds and cannot easily capture the broad range of audio frequencies found in egocentric videos. EgoSonics addresses these limitations by building on the strength of latent diffusion models for conditioned audio synthesis. We first encode and process audio and video data into a form suitable for generation. The encoded data is used to train our model to generate audio tracks that capture the semantics of the input video. Our proposed SyncroNet builds on top of ControlNet to provide control signals that enable temporal synchronization to the synthesized audio. Extensive evaluations show that our model outperforms existing work in audio quality and in our newly proposed synchronization evaluation method. Furthermore, we demonstrate downstream applications of our model in improving video summarization.
Method
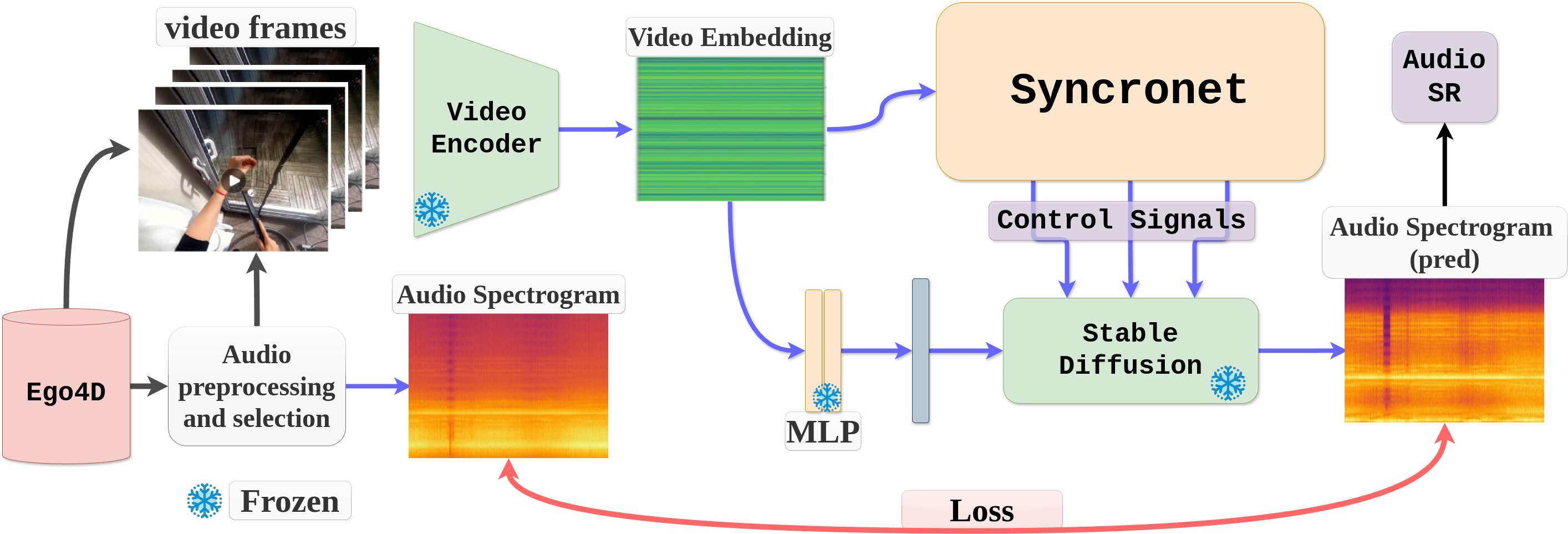
The overall architecture of our proposed method - EgoSonics. The input video frames are encoded through a video encoder to get video embedding. This video embedding goes to the SyncroNet which generates several control signals to control the generation of audio spectrograms by providing pixel-level temporal control to a pre-trained Stable Diffusion. An MLP translates the video embedding into text embedding for SD. The loss between the audio spectrogram and audio spectrogram (pred) is used to train SyncroNet.
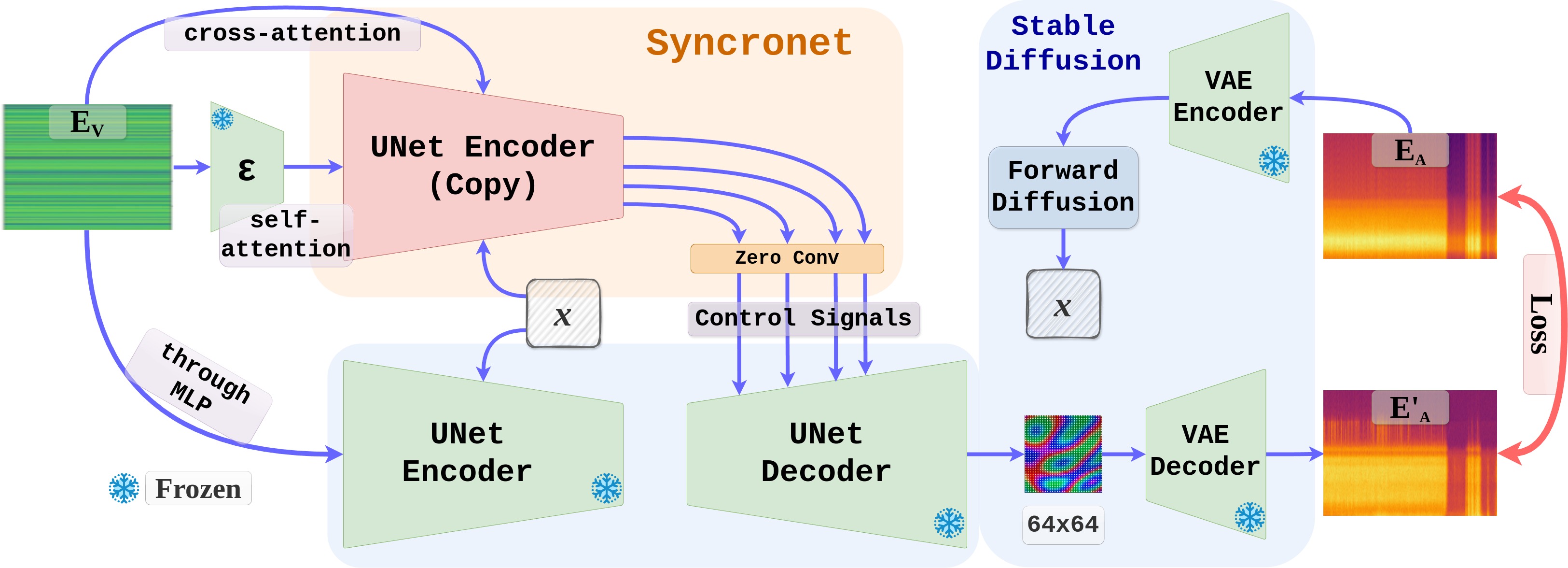
The following figure describes the training of Syncronet model. A trainable copy of Stable Diffusion’s UNet encoder generates control signals through zero convolution layers, providing pixel-level control to the pretrained UNet Decoder model. The UNet decoder generates a 64x64 encoded feature map, which goes through VAE decoder to generate the predicted audio spectrogram.
Comparison with Baseline
Below are examples of video-to-audio generation on unseen Ego4D clips for our method and the baseline.
(Unmute videos to hear the audio.)
GT/Original EgoSonics(Ours) Baseline
Failure Cases
Although EgoSonics can generate good-quality audio for egocentric videos, there are a few limitations to our approach. One of the things we observed in some of our generated samples is the misalignment due to the lack of rich visual information, which might result from occlusions. We are also limited by the amount of data available for training. For example, since there are few samples of musical instruments in the Ego4D dataset, our model doesn’t perform very well on such videos. We believe that such challenges can be solved by training our model on a large dataset comprising millions of audio-video pairs.
Citations
@article{rai2024egosonics,
title={EgoSonics: Generating Synchronized Audio for Silent Egocentric Videos},
author={Rai, Aashish and Sridhar, Srinath},
journal={IEEE/CVF Winter Conference on Applications of Computer Vision},
year={2025}
}
Contact
Aashish Rai (aashish@brown.edu)