CVPR 2023
CLIP-Sculptor: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Natural Language
1 Autodesk AI Research
2 Brown University
3 Columbia University
Overview

Recent works have demonstrated that natural language can be used to generate and edit 3D shapes. However, these methods generate shapes with limited fidelity and diversity. We introduce CLIP-Sculptor, a method to address these constraints by producing high-fidelity and diverse 3D shapes without the need for (text, shape) pairs during training. CLIP-Sculptor achieves this in a multi-resolution approach that first generates in a low-dimensional latent space and then upscales to a higher resolution for improved shape fidelity. For improved shape diversity, we use a discrete latent space which is modeled using a transformer conditioned on CLIP’s image-text embedding space. We also present a novel variant of classifier-free guidance, which improves the accuracy-diversity trade-off. Finally, we perform extensive experiments demonstrating that CLIP-Sculptor outperforms state-of-the-art baselines.
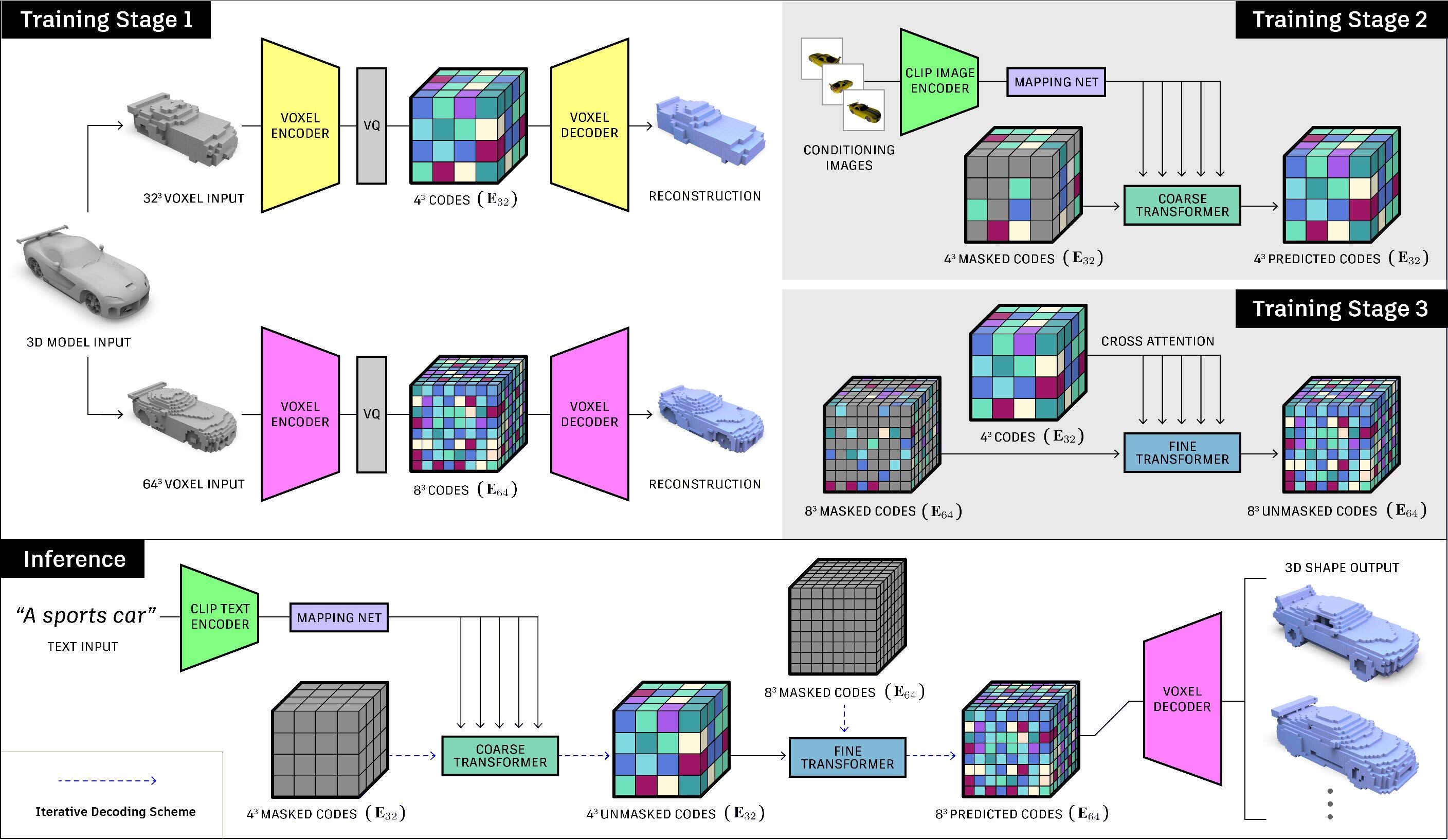
Method Overview
The CLIP-Sculptor architecture during training (top) and inference (bottom). CLIP-Sculptor is trained in three stages. In Stage 1, we train two separate VQ-VAE models for low and high resolution voxel grids. In Stage 2 we train a coarse transformer conditioned on a CLIP embedding to generate low resolution VQ-VAE latent grids. In Stage 3, we train a fine transformer to perform super resolutionon these latent grids. During inference, a text prompt is passed through the CLIP text encoder and used to condition the coarse transformer to generate a coarse latent grid. This coarse grid is then used to condition the fine transformer to generate a fine latent grid. Finally, this fine latent grid is then passed through the Training Stage 1 high resolution VQ-VAE decoder to generate the output shape.”.
Results on ShapeNetCore (13 Categories)
Multiple generated 3D shapes by CLIP-Sculptor with different text input. The text inputs are (sub-)category names of ShapeNet13, and phases with semantic attributes.
"an airplane"

"a ak-47"

"a delta wing"

"an jet"

"a machine gun"

"a office chair"

"a round shaped lamp"

"a round table"

"an egg chair"

Results on ShapeNetCore (55 Categories)
"a truck"

"a bathtub"

"a bowl"

"a formula one car"

"a motor bike"

"a round guitar"

"a round jar"

"a trash can"

Citation
@InProceedings{sanghi2023clipsculptor,
title={CLIP-Sculptor: Zero-Shot Generation of High-Fidelity and Diverse Shapes from Natural Language},
author={Sanghi, Aditya and Fu, Rao and Liu, Vivian and Willis, Karl and Shayani, Hooman and Khasahmadi, Amir Hosein and Sridhar, Srinath and Ritchie, Daniel},
booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}}
Acknowledgements
This work was supported by AFOSR grant FA9550-21-1-0214.
Contact
Aditya Sanghi (aditya.sanghi@autodesk.com)
Rao Fu (rao_fu@brown.edu)